CozyCL: a comfortable OpenCL library
CozyCL is a very simple, minimalist OpenCL library. You can run programs on your graphics card pretty easily with it, without the need to know anything about the data types of the base libraries (at least for the host program). When I started to learn about GPU programming in the previous weeks, I found even the most handy C++ bindings pretty time-consuming for a beginner, who is mostly interested in getting positive feedback and sense of achievement after a couple of initial attempts.
Download
- Source code: CozyCL_src.zip (C++)
- Example program: CozyCL_x64.zip (x64, Windows, console)
Usage
After you have prepared your work environment (which for you should google tutorials specific to your graphics card and IDE), it’s quite easy to start a program:
try { cozyCl = new CozyCL(0, 0, "test_program.cl", "test_function", 1, 10); cozyCl->writeMemory(0, test_data, 10, 0); cozyCl->startKernel(0, 10, 5); cozyCl->waitForAll(); cozyCl->readMemory(0, test_data, 10, 0); } catch (FException *ex) { ex->Print(); } |
CozyCL loads the program from the test_program.cl file, compiles it, selects the “test_function” for the later creation of kernels, and allocates 1 memory object of 10 bytes on the device. Then we copy 10 bytes into the memory of the graphics card, from the previously prepared test_data array. The startKernel() method spawns 10 work items in two (5-5) work-groups, to start working on the transmitted data.
And here’s the content of the test_program.cl file:
__kernel void test_function(__global char* data, long size) { data[get_global_id(0)] += size - get_global_id(0) - 1; } |
These lines are part of the example program which you can download from above. That program also queries the available platforms and devices on the host machine. Its output:
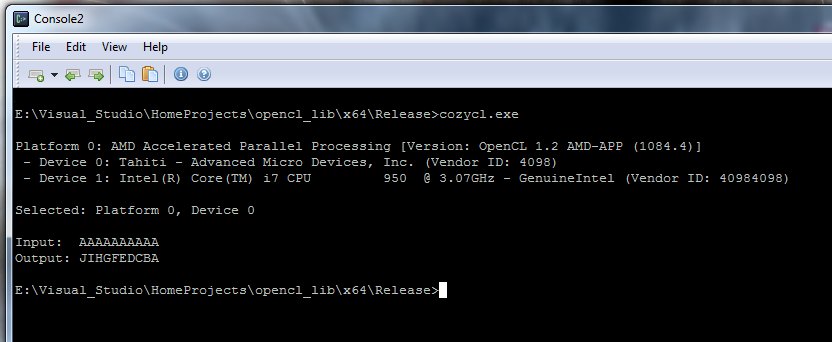
Here you can see what the test_program.cl does. The test_function – as a kernel – had been assigned to 10 work-items, and each of these work items incremented a different character in the “AAAAAAAAAA” string, based on their global ID.
Static query functions
CozyCL has two handy static functions, which can be used to query the available platforms and devices:
vector<string> platforms = CozyCL::getPlatforms(); for (int i = 0; i < platforms.size(); i++) { std::cout << "Platform " << i << ": " << platforms[i] << std::endl; } vector<string> devices = CozyCL::getDevices(0); for (int i = 0; i < devices.size(); i++) { std::cout << " - Device " << i << ": " << devices[i] << std::endl; } |
It is important to notice that the platform and device IDs used by CozyCL are not the real device IDs, but the index (position) of the items in these vector arrays above (see). So the first platform’s ID is 0, while the second’s ID is 1. The ID of the first device in a Platform is 0, while the second’s is 1, etc. So the device ID is not unique globally, but only inside a platform.
Because these functions are static, you don’t have to instantiate the CozyCL class to call them.
Memory objects
On many cards it is not possible to allocate the full memory of the card in one call. Using multiple memory objects allows to use all memory on the graphics card. My card for example has 6 GB RAM, but only max 2GB can be allocated at once (as an OpenCL memory buffer).
I was thinking a lot, how to allow full memory access without making the API too complicated, and ended up with this:
The desired number and size of memory objects can be defined in the last two operands of the constructor:
cozyCl = new CozyCL(0, 0, "test_program.cl", "test_function", 4, 1073741824); |
So this allocates 4 memory objects (buffers in reality), each of 1073741824 bytes, which is 1 GB.
In the previous example the 0 in the first argument of these calls, was actually a reference to the first memory object:
cozyCl->writeMemory(0, test_data, 10, 0); cozyCl->startKernel(0, 10, 5); //... cozyCl->readMemory(0, test_data, 10, 0); |
So the ID of the first memory object is 0, the ID of the second is 1, etc…
Each memory object requires a different startKernel() call, and this call doesn’t block, it doesn’t wait for the GPU to finish, which allows you to get the work started on the other buffers as well:
cozyCl->writeMemory(0, input1, 1073741824, 0); cozyCl->writeMemory(1, input2, 1073741824, 0); cozyCl->startKernel(0, 1024, 64); cozyCl->startKernel(1, 1024, 64); cozyCl->waitForAll(); cozyCl->readMemory(0, output1, 1073741824, 0); cozyCl->readMemory(1, output2, 1073741824, 0); |
You only need to delete the CozyCL object to free up the resources. Its destructor releases all OpenCL objects automatically.
delete cozyCl; |
Kernel function arguments
Because CozyCL sets the arguments for you automatically, you have to use specific parameters in your kernels:
- The first have to be a global pointer. In this the work items receive a pointer to their memory block in the global memory of the graphics card.
- The second must be a long integer, in which the size of this block will be passed. This could allow to make the kernel code more flexible.
In the example program “__global char*” was used as a pointer type, but any global pointer can be used. Here are two other good examples:
__kernel void test_function1(__global double* data, long size) { ... } __kernel void test_function2(__global long* data, long size) { ... } |
Function reference
Only for the non-trivial functions. See the others in the previous examples.
CozyCL::CozyCL( uInt32 platform_id, uInt32 device_id, char *program_FilePath, char *kernel_func, uInt32 memoryObject_num, uInt64 memoryObject_memSize) |
This is the constructor, its parameters are:
- platform_id: The ID of the platform. (see previous explanation on IDs)
- device_id: The platform dependent ID of the device. (see previous explanation on IDs)
- program_FilePath: relative or absolute path to the OpenCL C program file.
- kernel_func: the name of the function, which you want to use as a kernel for the spawned work items.
- memoryObject_num: The number of memory objects (buffers) to allocate.
- memoryObject_memSize: The size of each memory object in bytes.
void CozyCL::writeMemory( uInt32 memoryObject_id, void *host_addr, uInt64 size, uInt64 device_addr) |
Copies a region of memory from the host machine into the global memory of the graphics card.
- memoryObject_id: Which memory object (buffer) to use in the graphics card.
- host_addr: pointer to the data in the memory of the host machine.
- size: The size of the data, in bytes.
- device_addr: The destination address in the graphics card to copy. This is a relative address inside the buffer. An offset. Use 0 for the first byte of the buffer and “size – 1″ for its last byte.
void CozyCL::readMemory( uInt32 memoryObject_id, void *host_addr, uInt64 size, uInt64 device_addr) |
Copies data from the global memory of the graphics card into the host machine.
- memoryObject_id: Which memory object (buffer) to use in the graphics card.
- host_addr: pointer to the buffer in the memory of the host machine.
- size: The size of the data, in bytes.
- device_addr: The source address in the graphics card to copy from. This is a relative address inside the buffer. An offset. Use 0 for the first byte of the buffer and “size – 1″ for its last byte.
void CozyCL::startKernel( uInt32 memoryObject_id, uInt32 global_size, uInt32 local_size) |
Deploys the kernels to the GPU. Starts the program.
- memoryObject_id: memory object (buffer) id
- global_size: total size of work items
- local_size: the number of work items in a work-group.
Notice that:
work_group_number = global_size / local_size
And the number of work groups is equal to the computing units (CU) used in the GPU.
For more information about global and local size, read: http://www.khronos.org/registry/cl/specs/opencl-1.2.pdf